Hace algunos días me topé con la tarea de realizar una migración de las aplicaciones de un IIS a otro servidor. El proceso inició con un análisis de uso de las aplicaciones, para identificar cuáles tenían muy poco o nulo uso en el último año y descartarlas de la migración.
De esta primera etapa voy a hablar en esta publicación.
Herramientas utilizadas
Para esta tarea utilicé las siguientes herramientas:
PowerShell — para obtener el listado de aplicaciones del IIS mediante el módulo WebAdministration y orquestar la ejecución del análisis.
Log Parser 2.2 — herramienta de consola gratuita de Microsoft que permite hacer queries de SQL sobre los archivos de log del IIS en formato W3C. La puedes descargar directamente del sitio de Microsoft buscando “Log Parser 2.2”.
Se requirieron privilegios de administrador y el módulo WebAdministration instalado en PowerShell.
El script de análisis
Para realizar el análisis me apoyé de un script de PowerShell cuya tarea es obtener el listado de aplicaciones del IIS y consultar, mediante un query de Log Parser, el estadístico de uso de cada una, clasificándolas en 3 niveles de riesgo según los días transcurridos desde su último acceso exitoso.
La consulta que se ejecuta sobre los logs filtra únicamente peticiones exitosas (código HTTP menor a 400) y excluye recursos estáticos como CSS, JavaScript, imágenes y documentos, de modo que el resultado refleja el uso real de páginas y endpoints, no el tráfico de archivos.
Los niveles de riesgo que manejo son:
Nivel
Condición
BAJO
Último acceso hace menos de 180 días
MEDIO
Último acceso entre 180 y 365 días
ALTO
Sin acceso exitoso en más de 365 días
El umbral de 365 días es configurable en la variable $thresholdDays al inicio del script.
El script quedó de la siguiente forma:
# RevisionIISv2.ps1
# ============================================================
# CONFIG
$logParserPath = "C:\Program Files (x86)\Log Parser 2.2\LogParser.exe"
$logRoot = "C:\inetpub\logs\LogFiles"
$outputCsv = "C:\Revision IIS\IIS_Auditoria_V2.csv"
$thresholdDays = 365
Import-Module WebAdministration
$resultados = @{}
foreach ($site in Get-Website) {
$siteId = $site.ID
$logPath = Join-Path $logRoot "W3SVC$siteId"
if (!(Test-Path $logPath)) { continue }
$query = @"
SELECT cs-uri-stem,
COUNT(*) AS Hits,
MAX(TO_TIMESTAMP(date, time)) AS UltimoAcceso
FROM $logPath\*.log
WHERE sc-status < 400
AND cs-uri-stem NOT LIKE '%.css'
AND cs-uri-stem NOT LIKE '%.js'
AND cs-uri-stem NOT LIKE '%.png'
AND cs-uri-stem NOT LIKE '%.jpg'
AND cs-uri-stem NOT LIKE '%.gif'
AND cs-uri-stem NOT LIKE '%.ico'
AND cs-uri-stem NOT LIKE '%.pdf'
AND cs-uri-stem NOT LIKE '%.doc%'
AND cs-uri-stem NOT LIKE '%.xls%'
AND cs-uri-stem NOT LIKE '%health%'
GROUP BY cs-uri-stem
"@
$tmpFile = [System.IO.Path]::GetTempFileName()
& $logParserPath $query -i:IISW3C -o:CSV > $tmpFile
$csv = Import-Csv $tmpFile
Remove-Item $tmpFile
foreach ($row in $csv) {
if ([string]::IsNullOrWhiteSpace($row.UltimoAcceso)) { continue }
try { $fecha = [datetime]$row.UltimoAcceso }
catch { continue }
$diasSinUso = (New-TimeSpan -Start $fecha -End (Get-Date)).Days
$appPath = "/"
if ($row.'cs-uri-stem' -match "^/([^/]+)") {
$appPath = "/" + $matches[1]
}
$key = "$($site.Name)|$appPath"
if ($resultados.ContainsKey($key)) {
if ($fecha -gt $resultados[$key].UltimoAcceso) {
$resultados[$key].UltimoAcceso = $fecha
$resultados[$key].DiasSinUso = $diasSinUso
$resultados[$key].UltimaUrl = $row.'cs-uri-stem'
$resultados[$key].Riesgo = if ($diasSinUso -gt $thresholdDays) { 'ALTO' }
elseif ($diasSinUso -gt 180) { 'MEDIO' }
else { 'BAJO' }
}
$resultados[$key].Hits += [int]$row.Hits
} else {
$tipo = if ($appPath -match 'api|svc|service') { 'API' } else { 'Web' }
$riesgo = if ($diasSinUso -gt $thresholdDays) { 'ALTO' }
elseif ($diasSinUso -gt 180) { 'MEDIO' }
else { 'BAJO' }
$resultados[$key] = [PSCustomObject]@{
Sitio = $site.Name
Aplicacion = $appPath
Hits = [int]$row.Hits
UltimaUrl = $row.'cs-uri-stem'
UltimoAcceso = $fecha
DiasSinUso = $diasSinUso
Tipo = $tipo
Riesgo = $riesgo
}
}
}
}
# Exportar ordenado por días sin uso (mayor primero)
$resultados.Values |
Sort-Object DiasSinUso -Descending |
Export-Csv $outputCsv -NoTypeInformation -Encoding UTF8
Write-Host "Reporte generado en: $outputCsv"
Resultado del script
El resultado del script es un archivo CSV con la siguiente estructura:
Columna
Descripción
Sitio
Nombre del sitio IIS (ej. Default Web Site)
Aplicacion
Path de la aplicación detectada (ej. /MiApp)
Hits
Total de peticiones exitosas acumuladas en todos los logs
UltimaUrl
La última URL exacta registrada para esa aplicación
UltimoAcceso
Fecha y hora del último acceso exitoso
DiasSinUso
Días transcurridos desde el último acceso hasta hoy
Tipo
Web o API, detectado por el patrón en el path
Riesgo
BAJO, MEDIO o ALTO según los días sin uso
Con este CSV ya puedo validar y descartar las aplicaciones que ya no son relevantes o tienen poco o nulo uso. El proceso es manual: abro el archivo en Excel, ordeno por DiasSinUso de mayor a menor y voy decidiendo cuáles se migran. Las de Riesgo ALTO son las candidatas a descartar, aunque siempre hay que validar con el negocio, ya que puede haber sistemas con uso estacional que solo se acceden unos días al año pero son críticos.
Posterior a esto, el siguiente paso es exportar la configuración de cada aplicativo seleccionado e importarla en el nuevo servidor, pero de esa parte les hablaré en mi próxima publicación.
Los benchmarks publicados por los fabricantes de modelos de IA suelen mostrar sus versiones más grandes corriendo en hardware de servidor. Pero, ¿qué pasa cuando los pruebas en tu propio equipo, con una GPU de consumo y condiciones reales de uso?
Esto es exactamente lo que hice: tomé ocho de los modelos más relevantes disponibles hoy en Ollama, los corrí en el mismo hardware, con las mismas preguntas, y medí no solo la velocidad de generación sino también el retraso por pensamiento, el consumo de VRAM, el overflow a RAM y el uso de CPU. Los resultados me obligaron a revisar mis opiniones más de una vez — este artículo refleja la tercera y definitiva ronda de evaluación.
El foco especial está en Gemma 4 de Google DeepMind, un modelo que en las comparativas publicadas aparece por debajo de otros competidores, pero que en mis pruebas reales demostró ser consistentemente el mejor para uso cotidiano en hardware de 12 GB.
Hardware usado para las pruebas
CPU: AMD Ryzen 7 5700G (8 núcleos, arquitectura Zen 3)
RAM: 32 GB DDR4 a 3200 MHz
GPU: Gigabyte GeForce RTX 3060 12 GB GDDR6
Almacenamiento de modelos: HDD 1.8 TB
Sistema operativo: Debian 12 Bookworm
Motor de inferencia: Ollama en Docker con CUDA
La RTX 3060 de 12 GB representa el punto de entrada más sensato para IA local en 2026: suficiente VRAM para correr modelos de 14B parámetros completamente en GPU, con una relación precio/rendimiento difícil de superar en el mercado de segunda mano.
Una métrica que nadie menciona: el retraso por pensamiento
Antes de entrar en los datos, hay una métrica que define la experiencia de uso más que cualquier otra y que rara vez aparece en las comparativas: el retraso por pensamiento.
Los modelos modernos con capacidad de razonamiento generan un proceso interno de análisis antes de producir la respuesta visible. Durante ese tiempo, el usuario ve una pantalla en blanco o un indicador de carga. Dependiendo del modelo y la complejidad de la pregunta, ese retraso puede ir de segundos a más de un minuto.
En la práctica, un modelo que genera a 45 tokens por segundo pero tarda 60 segundos en empezar puede sentirse más lento que uno que genera a 30 t/s con 6 segundos de retraso. Evaluar modelos únicamente por velocidad de generación es engañoso.
Tabla comparativa completa
Modelo
Velocidad (t/s)
VRAM usada
Overflow RAM
CPU
Arranque frío
Retraso thinking
gemma4:e4b
73.06
~10 GB
0 GB
~0%
~90 seg
~6 seg
qwen3.5:9b
45.22
8.8 GB
0 GB
~0%
~60 seg
hasta 60 seg
qwen3.5:9b (/nothink)
45.22
8.8 GB
0 GB
~0%
~60 seg
~10 seg
phi4-reasoning:14b
21.28
~12 GB
~2 GB
~3%
~90 seg
~120 seg
mistral-nemo:12b
46.12
7.7 GB
0 GB
~0%
~30 seg
0 seg
deepseek-r1:14b
33.54
~10 GB
0 GB
~0%
~60 seg
~20 seg
qwen3:14b
32.58
10 GB
0 GB
~0%
~20 seg
~13 seg
mistral-small3.2:24b
6.58
~12 GB
~5 GB
31%
~170 seg
0 seg
gemma4:26b
18
12 GB
8 GB
41%
~240 seg
~50 seg
Ranking final por calidad de respuesta
🥇 gemma4:e4b — Mejor calidad general, más rápido, multimodal
🥈 qwen3.5:9b — Buen contenido, excelente formato, thinking lento
🥉 phi4-reasoning:14b — Contenido similar a Qwen3.5, formato menos pulido
4️⃣ mistral-nemo:12b — Sólido, rápido, sin esperas
5️⃣ deepseek-r1:14b — Razonamiento profundo y visible
6️⃣ qwen3:14b — Competente pero superado por la nueva generación
7️⃣ mistral-small3.2:24b — No escala bien en 12 GB de VRAM
8️⃣ gemma4:26b — Descartado en este hardware
Análisis detallado por modelo
1. Gemma 4 E4B — El mejor modelo para hardware de 12 GB
Gemma 4 es la familia de modelos open source más reciente de Google DeepMind, lanzada en abril de 2026. La variante E4B es el punto dulce de la familia para GPUs de 12 GB: cabe completamente en VRAM, no toca la RAM del sistema y no genera carga en el CPU.
¿Qué tiene de especial Gemma 4?
Multimodal nativo: procesa texto, imágenes y audio en el mismo modelo, sin herramientas adicionales
Thinking mode con mínimo retraso: solo 6 segundos antes de la primera respuesta — el más bajo del grupo
128K tokens de contexto: suficiente para proyectos de código extensos o documentos largos
Arquitectura MoE eficiente: 4.5B parámetros efectivos en un paquete de 9.6 GB
Datos reales medidos
Velocidad: 73.06 tokens por segundo
VRAM: ~10 GB, sin overflow
CPU: ~0% durante generación
Arranque en frío: ~90 segundos
Retraso por thinking: ~6 segundos
A 73 tokens por segundo, el modelo genera texto mucho más rápido de lo que puedes leerlo. Es la experiencia de uso más fluida que he tenido con un modelo local en hardware de consumo.
En las comparativas publicadas, Gemma4 aparece un poco por debajo de modelos como Qwen3.5 en los rankings generales. Sin embargo, en mis pruebas reales la calidad percibida de las respuestas supera a todos los demás del grupo. Hay una brecha clara entre los benchmarks de laboratorio con versiones cloud y la experiencia de uso real con versiones locales en hardware de consumo.
La capacidad multimodal añade una dimensión completamente nueva: pasar una captura de pantalla de un error, un diagrama de arquitectura o un documento y recibir análisis inmediato es algo que ningún otro modelo de esta comparativa ofrece de forma tan integrada.
Veredicto: primer lugar en calidad de respuesta y primer lugar en velocidad. La mejor opción para hardware de 12 GB sin discusión.
2. Qwen 3.5 9B — Buen formato, contenido sobrevalorado por los benchmarks
Qwen3.5 es la familia más reciente de Alibaba. En las comparativas de su versión cloud (Qwen3.5-Plus) aparece al nivel de GPT-5.2 o Claude Opus 4.5. La versión local de 9B es una historia diferente.
Las respuestas tienen muy buen formato y presentación: estructura clara, uso apropiado de listas y encabezados, organización visual cuidada. Sin embargo, el contenido en sí no está a la altura de lo que sugieren los benchmarks de sus versiones cloud. La apariencia de calidad que da el formato puede crear una primera impresión mejor de la que merece el fondo de las respuestas.
El thinking mode introduce el mayor retraso del grupo: hasta 60 segundos antes de la primera respuesta en preguntas complejas. Desactivarlo con /nothink reduce ese tiempo a unos 10 segundos, haciendo el modelo mucho más usable en el día a día, aunque sacrificando parte de su capacidad de razonamiento.
Veredicto: segundo lugar en calidad. Mejor con /nothink para uso cotidiano. Los benchmarks de su versión cloud no reflejan el rendimiento real de la versión local de 9B.
3. Phi4 Reasoning 14B — Potencial sin pulir
Phi4-reasoning es el modelo de razonamiento de Microsoft, parte de la familia Phi4. Con 14B parámetros genera a 21.28 t/s con un ligero overflow de 2 GB a RAM y apenas 3% de uso de CPU.
La calidad del contenido es comparable a Qwen3.5:9b — buen nivel de análisis técnico y respuestas bien razonadas. La diferencia está en el formato: donde Qwen3.5 presenta respuestas visualmente organizadas, Phi4-reasoning tiende a entregar el mismo nivel de contenido de forma más cruda, sin la estructuración visual que facilita la lectura.
Es un modelo prometedor que probablemente mejore con versiones futuras. Para quien prioriza el contenido sobre la presentación, es una alternativa válida en el rango de 14B.
Veredicto: tercer lugar en calidad. Mismo nivel de contenido que Qwen3.5:9b, presentación menos cuidada.
4. Mistral Nemo 12B — El equilibrado que nadie menciona
Mistral Nemo es un modelo que suele quedar fuera de los titulares pero que en las pruebas resulta ser una opción muy práctica. Con solo 7.7 GB de VRAM cabe en GPUs de 8 GB, genera a 46.12 t/s sin ningún retraso por thinking y sin overflow a RAM.
Su valor principal es la consistencia: el arranque más rápido del grupo (~30 segundos), respuesta inmediata sin pausa de pensamiento y compatibilidad con hardware más modesto. La calidad de sus respuestas es competente aunque no destaca especialmente frente a los primeros tres modelos del ranking.
Veredicto: cuarto lugar. La mejor opción para GPUs de 8 GB y para quien necesita respuesta inmediata sin ninguna configuración adicional.
5. DeepSeek R1 14B — El especialista en razonamiento visible
DeepSeek R1 está diseñado específicamente para razonamiento profundo y transparente. Su proceso de pensamiento es visible paso a paso, lo que permite entender no solo la respuesta sino el camino para llegar a ella. Esto tiene valor real en debugging complejo, análisis de sistemas o decisiones arquitectónicas donde el proceso importa tanto como el resultado.
A 33.54 t/s sin overflow a RAM, el rendimiento es sólido. El retraso de ~20 segundos por thinking es aceptable dado el nivel de análisis que produce. Quinto lugar en calidad de respuesta del grupo.
Veredicto: quinto lugar en calidad general. Recomendado cuando el razonamiento visible y trazable es un requisito.
6. Qwen3 14B — Superado por la nueva generación
Qwen3:14b fue durante meses una referencia sólida para tareas de código y arquitectura. A 32.58 t/s sin overflow, sigue siendo competente, y el modo /think activa razonamiento paso a paso cuando se necesita.
El problema es que modelos más nuevos y en algunos casos más pequeños lo superan en calidad. Qwen3.5:9b entrega mejor resultado siendo más pequeño. Phi4-reasoning ofrece análisis comparable con reasoning más explicado. Qwen3:14b ya no es la primera opción en ninguna categoría de esta comparativa.
Veredicto: sexto lugar. Todavía funcional pero sin ventaja frente al resto del grupo.
7. Mistral Small 3.2 24B — No escala bien en 12 GB de VRAM
Mistral Small 3.2 tiene buenas credenciales: 24B parámetros, arquitectura MoE, sin retraso por thinking. En hardware con 24 GB de VRAM probablemente brillaría. En una GPU de 12 GB los números son difíciles de defender.
6.58 t/s de generación, 5 GB de overflow a RAM, 31% de CPU constante y casi 3 minutos de arranque en frío. Para obtener una respuesta comparable a la de los modelos del top 3, el tiempo de espera total es varias veces mayor. La ausencia de retraso por thinking no compensa la lentitud general del modelo en este hardware.
Veredicto: séptimo lugar. Necesita 24 GB de VRAM para ser competitivo. No recomendado en 12 GB.
8. Gemma4 26B — La versión grande que decepciona en este hardware
Con 8 GB de overflow a RAM, 41% de CPU constante, 4 minutos de arranque y ~50 segundos de retraso por thinking, el Gemma4:26b ofrece la peor experiencia de uso del grupo en este hardware. Su versión pequeña, el E4B, es superior en todos los aspectos prácticos cuando la VRAM disponible es de 12 GB.
La mejora de calidad frente al E4B no justifica en ningún caso la penalización de rendimiento. Para este modelo se necesita idealmente una GPU de 24 GB donde pueda correr completamente en VRAM.
Veredicto: último lugar. Usar gemma4:e4b en su lugar para este nivel de hardware.
¿Cuándo usar cada modelo?
Para el día a día y consultas cotidianas: gemma4:e4b. Velocidad, calidad y soporte multimodal. Sin competencia en este hardware.
Para análisis de imágenes, diagramas o documentos: gemma4:e4b. Es el único modelo del grupo con soporte multimodal real integrado.
Para análisis técnico con buen formato: qwen3.5:9b con /nothink. Respuestas bien estructuradas visualmente para documentación o explicaciones.
Para razonamiento trazable paso a paso: deepseek-r1:14b. Cuando el proceso importa tanto como la respuesta.
Para GPUs de 8 GB o menos: mistral-nemo:12b. Cabe cómodo, responde sin esperas y no requiere configuración.
Para autocomplete en el editor: deepcoder:1.5b o phi4-mini:3.8b. Modelos ultraligeros que se quedan cargados en background sin impactar el rendimiento de los modelos principales.
El stack que uso actualmente
gemma4:e4b — modelo principal para todo el trabajo cotidiano y análisis de imágenes
qwen3.5:9b — para cuando necesito respuestas bien formateadas o análisis con thinking activado
deepseek-r1:14b — para debugging complejo y razonamiento técnico profundo
mistral-nemo:12b — para consultas rápidas sin ninguna espera
deepcoder:1.5b — autocomplete permanente en VS Code y Visual Studio
Lo que viene en esta serie
Este análisis de modelos es el segundo artículo de una serie sobre IA local. Los próximos temas que planeo cubrir:
Integración con clientes de codificación: Claude Code, Codex y OpenCode — cómo conectarlos a tu servidor Ollama local y qué diferencias hay entre ellos para el trabajo diario de desarrollo
Compatibilidad con GitHub Copilot: ¿es posible usar tus modelos locales como backend de Copilot?
Implementación de un sistema RAG: cómo conectar tu propia base de documentos a los modelos para obtener respuestas basadas en tu conocimiento privado, sin que nada salga de tu red
Si quieres recibir notificación cuando salgan esos artículos, suscríbete al blog.
Conclusiones
Tres lecciones que me llevé de estas pruebas después de tres rondas de evaluación:
1. Los benchmarks de laboratorio no predicen la experiencia real en hardware de consumo. Gemma4 aparece por debajo de Qwen3.5 en muchas comparativas publicadas. En hardware real, Gemma4:e4b gana en calidad percibida, velocidad y experiencia de uso. La versión cloud de un modelo y su versión local de 9B son productos muy distintos.
2. El retraso por thinking puede arruinar un modelo perfectamente capaz. Qwen3.5:9b tiene buenas respuestas pero su retraso de hasta 60 segundos por thinking lo hace frustrante para uso cotidiano. Desactivarlo con /nothink es la solución práctica, aunque implica sacrificar parte de su capacidad de razonamiento.
3. Con una RTX 3060 de 12 GB ya se puede hacer trabajo serio con IA local. Gemma4:e4b a 73 t/s con soporte multimodal, completamente en local, sin suscripciones y sin que tus datos salgan de tu red. Eso habría parecido imposible hace dos años en hardware de consumo.
¿Has probado alguno de estos modelos? ¿Tu experiencia coincide con la mía o llegaste a conclusiones diferentes? Los comentarios están abiertos.
¿Cansado de los límites de uso, las suscripciones mensuales y la preocupación de que tus conversaciones con una IA sean almacenadas en servidores de terceros? Existe una alternativa real: montar tu propio servidor de inteligencia artificial en casa, con hardware que probablemente ya tienes o puedes conseguir por una fracción del costo de una suscripción anual.
En este artículo te explico exactamente cómo lo hice, qué hardware usé, qué software necesitas y cómo dejarlo funcionando desde cualquier dispositivo de tu red local.
¿Por qué correr una IA localmente?
Antes de entrar al tutorial, vale la pena entender por qué tiene sentido hacer esto:
Privacidad total: tus conversaciones, tu código y tus documentos nunca salen de tu red. Nadie los lee, nadie los usa para entrenar modelos.
Sin costo por uso: una vez que tienes el hardware, el costo marginal de cada consulta es prácticamente cero (electricidad).
Sin límites de mensajes: no hay “has alcanzado tu límite diario” ni planes de pago por niveles.
Funciona offline: no dependes de internet ni de la disponibilidad de servidores externos.
Control total: tú decides qué modelos corres, con qué configuración y quién tiene acceso.
¿Qué es Ollama y qué es Open WebUI?
Ollama es una herramienta open source que permite descargar, gestionar y servir modelos de lenguaje grandes (LLMs) localmente. Funciona como un servidor con API REST, lo que significa que cualquier aplicación en tu red puede hacer consultas a tus modelos como si fuera una API de OpenAI.
Open WebUI es una interfaz web tipo ChatGPT que se conecta a Ollama. Te da una experiencia visual amigable desde cualquier navegador, sin necesidad de usar la terminal para interactuar con los modelos.
Juntos forman un stack completo: Ollama gestiona los modelos y la inferencia, Open WebUI le da la interfaz. Docker se encarga de que todo corra de forma aislada y reproducible.
Requerimientos de hardware
La clave para un servidor de IA funcional es la GPU. Los modelos de lenguaje corren dramáticamente más rápido en GPU que en CPU — hablamos de una diferencia de 10x a 15x en velocidad de generación.
Hardware mínimo recomendado
CPU: procesador x86-64 de 6 o más núcleos (AMD Ryzen o Intel Core de generación reciente)
RAM: 16 GB DDR4 mínimo, 32 GB recomendado. La RAM del sistema sirve como desbordamiento cuando los modelos no caben completamente en la VRAM de la GPU
GPU: NVIDIA con mínimo 8 GB de VRAM. La RTX 3060 de 12 GB es el punto dulce en relación precio/rendimiento para modelos locales
Almacenamiento: SSD de 256 GB para el sistema operativo y Docker. Un disco adicional (HDD o SSD) de al menos 500 GB para almacenar los modelos, ya que cada uno pesa entre 4 y 20 GB
Sistema operativo: Debian 12 (Bookworm) o Ubuntu 22.04/24.04 LTS
Hardware real usado en este tutorial
El servidor que uso como base para esta guía tiene las siguientes especificaciones:
Placa madre: MSI MPG B550 Gaming Plus
CPU: AMD Ryzen 7 5700G (8 núcleos)
RAM: 32 GB DDR4 a 3200 MHz
GPU: Gigabyte GeForce RTX 3060 12 GB
SSD: 256 GB M.2 NVMe PCIe 4.0 (sistema y Docker)
HDD: 1.8 TB (almacenamiento de modelos)
Sistema operativo: Debian 12 Bookworm
Con este hardware, modelos de 14B parámetros corren completamente en GPU a 25-35 tokens por segundo, y modelos más pequeños como Gemma4:e4b alcanzan 73 tokens por segundo, más rápido de lo que puedes leer.
Nota sobre GPU: aunque este tutorial usa una RTX 3060 de NVIDIA (que funciona con CUDA, el estándar de la industria), también es posible usar GPUs AMD con ROCm, aunque requiere configuración adicional. Si tu presupuesto es limitado, busca una RTX 3060 de 12 GB de segunda mano — es específicamente la versión de 12 GB, no la Ti que tiene 8 GB.
Software necesario
Antes de empezar, estos son los componentes de software que vamos a instalar:
Docker + Docker Compose: para ejecutar Ollama y Open WebUI como contenedores
Drivers NVIDIA: para que Linux reconozca y use la GPU
NVIDIA Container Toolkit: para que Docker pueda acceder a la GPU
Ollama (imagen Docker): el servidor de modelos
Open WebUI (imagen Docker): la interfaz web
Instalación paso a paso
Paso 1: Instalar Docker en Debian
Primero agrega los repositorios oficiales de Docker para Debian:
Verifica que Docker quedó instalado correctamente:
docker --version
Paso 2: Instalar drivers NVIDIA
Primero hay que agregar los repositorios non-free de Debian. Edita el archivo de fuentes:
nano /etc/apt/sources.list
Asegúrate de que cada línea incluya contrib non-free non-free-firmware:
deb http://deb.debian.org/debian/ bookworm main contrib non-free non-free-firmware
deb http://security.debian.org/debian-security bookworm-security main contrib non-free non-free-firmware
deb http://deb.debian.org/debian/ bookworm-updates main contrib non-free non-free-firmware
Luego instala el driver:
apt update
apt install -y nvidia-driver firmware-misc-nonfree
# Deshabilitar el driver genérico nouveau
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist-nouveau.conf
echo "options nouveau modeset=0" >> /etc/modprobe.d/blacklist-nouveau.conf
update-initramfs -u
reboot
Después del reinicio, verifica que el driver funciona:
nvidia-smi
Deberías ver tu GPU listada con el uso de VRAM y la versión del driver.
Paso 3: Instalar NVIDIA Container Toolkit
Este paquete permite que los contenedores Docker accedan a la GPU:
# Agregar el repositorio de NVIDIA
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
apt update
apt install -y nvidia-container-toolkit
# Configurar Docker para usar NVIDIA
nvidia-ctk runtime configure --runtime=docker
systemctl restart docker
Paso 4: Crear el docker-compose.yml
Crea un directorio de trabajo y el archivo de configuración:
mkdir -p ~/ollama
cd ~/ollama
nano docker-compose.yml
Importante: en la línea de volumen de Ollama, sustituye /ruta/a/tu/disco/ollama por la ruta real donde quieres almacenar los modelos. Si tienes un disco secundario montado (recomendado), apunta ahí. Los modelos pueden ocupar desde 4 GB hasta 20 GB cada uno.
Paso 5: Levantar los servicios
cd ~/ollama
docker compose up -d
Verifica que ambos contenedores están corriendo:
docker ps
Deberías ver ollama y open-webui en estado Up.
Paso 6: Verificar que Ollama usa la GPU
# Verificar que el contenedor ve la GPU
docker exec -it ollama nvidia-smi
Si ves tu GPU listada, todo está funcionando correctamente.
Paso 7: Descargar tu primer modelo
# Descargar Gemma4:e4b (recomendado para empezar)
docker exec -it ollama ollama pull gemma4:e4b
# Verificar que se descargó
docker exec -it ollama ollama list
Paso 8: Acceder a Open WebUI
Desde cualquier dispositivo en tu red local, abre el navegador y ve a:
http://IP_DE_TU_SERVIDOR:8080
La primera vez te pedirá crear una cuenta de administrador. Es local, no sale a internet. Una vez dentro, selecciona el modelo que descargaste y empieza a chatear.
Modelos recomendados para empezar
Con una GPU de 12 GB de VRAM, estos son los modelos que mejor funcionan:
Para uso general y velocidad máxima
docker exec -it ollama ollama pull gemma4:e4b
El modelo estrella para hardware como el nuestro. Cabe completamente en los 12 GB de VRAM, genera a 73 tokens por segundo (más rápido de lo que puedes leer), soporta imágenes y audio, y tiene thinking mode. Es el punto de partida ideal.
Para razonamiento y código
docker exec -it ollama ollama pull qwen3:14b
Excelente para tareas que requieren más razonamiento: analizar arquitecturas de software, revisar código, resolver problemas complejos. Genera a unos 30 tokens por segundo con buena calidad de respuesta.
Este modelo de 24B parámetros usa arquitectura MoE (Mixture of Experts), lo que le permite ofrecer la calidad de un modelo grande con un consumo razonable. Ocupa algo más de VRAM y desborda un poco a RAM del sistema, pero la calidad de sus respuestas es notablemente superior para análisis complejos.
Para autocomplete en el editor de código
docker exec -it ollama ollama pull deepcoder:1.5b
Un modelo ultraligero especializado en código. Solo ocupa 2 GB de VRAM y se puede dejar cargado en background para autocomplete en tiempo real desde VS Code o Visual Studio.
Verificar que todo funciona
Para confirmar que un modelo está corriendo en GPU y no en CPU:
docker exec -it ollama ollama ps
En la columna PROCESSOR deberías ver 100% GPU. Si ves CPU, revisa que el NVIDIA Container Toolkit esté instalado y que el docker-compose tenga la sección de GPU correctamente.
También puedes monitorear el uso de GPU en tiempo real mientras el modelo genera:
watch -n 1 nvidia-smi
Acceder desde otros dispositivos de la red
Una vez que el servidor está funcionando, cualquier dispositivo en tu red WiFi o LAN puede usar la IA:
Desde el navegador:http://IP_DEL_SERVIDOR:8080 para la interfaz web
Desde VS Code: instala la extensión Continue.dev y apunta el modelo a http://IP_DEL_SERVIDOR:11434
Desde Visual Studio: instala EntwineLLM y configura la misma URL
Desde Claude Code: configura las variables de entorno para apuntar a tu servidor local
Conclusión
Montar un servidor de IA local no es tan complicado como parece, y los beneficios son inmediatos: privacidad total, sin límites de uso y sin costo recurrente. Con una GPU de 12 GB de VRAM como la RTX 3060, puedes correr modelos que compiten de tú a tú con herramientas de pago para tareas cotidianas de desarrollo.
En la próxima publicación de esta serie hago un análisis detallado de los diferentes modelos que probé en este mismo servidor, incluyendo datos reales de velocidad, consumo de VRAM y calidad de respuesta para cada uno.
¿Tienes preguntas sobre algún paso de la instalación o quieres saber si tu hardware es compatible? Déjame un comentario abajo.
Si trabajas con SQL Server en entornos productivos, dominar la administración de permisos y el monitoreo es clave para mantener la seguridad, estabilidad y rendimiento del sistema.
En este artículo encontrarás desde comandos básicos hasta ejemplos más avanzados utilizados en escenarios reales.
🔐 Gestión de permisos (Nivel básico)
Dar permiso CONNECT en la base de datos
USE NombreBaseDatos;
GO
GRANT CONNECT TO NombreUsuario;
Permitir ver los Stored Procedures
GRANT VIEW DEFINITION ON DATABASE::TuBaseDeDatos TO TuUsuario;
Permitir ver el código de los SPs
GRANT VIEW DEFINITION TO TuUsuario;
Dar permiso EXECUTE sobre el esquema dbo o base de datos
GRANT EXECUTE ON SCHEMA::dbo TO NombreUsuario;
GRANT EXECUTE ON DATABASE::TuBaseDeDatos TO NombreUsuario;
Permisos sobre tablas o vistas específicas
GRANT SELECT ON dbo.MiTabla TO NombreUsuario;
GRANT INSERT, UPDATE, DELETE ON dbo.MiTabla TO NombreUsuario;
GRANT SELECT ON dbo.MiVista TO NombreUsuario;
GRANT SELECT ON DATABASE::MiDB NombreUsuario;
Acceso completo sobre un esquema
GRANT SELECT ON SCHEMA::dbo TO NombreUsuario;
GRANT INSERT, UPDATE, DELETE ON SCHEMA::dbo TO NombreUsuario;
🔐 Gestión avanzada de seguridad
Crear Login (nivel servidor)
CREATE LOGIN MiLogin WITH PASSWORD = 'PasswordSeguro123!';
Crear Usuario en la base de datos
USE NombreBaseDatos;
CREATE USER MiUsuario FOR LOGIN MiLogin;
Asignar roles predefinidos
ALTER ROLE db_datareader ADD MEMBER MiUsuario;
ALTER ROLE db_datawriter ADD MEMBER MiUsuario;
Crear un rol personalizado
CREATE ROLE RolLecturaEscritura;
GRANT SELECT, INSERT, UPDATE, DELETE ON SCHEMA::dbo TO RolLecturaEscritura;
ALTER ROLE RolLecturaEscritura ADD MEMBER MiUsuario;
Revocar permisos (REVOKE vs DENY)
-- Revoca el permiso (lo quita si existe)
REVOKE SELECT ON dbo.MiTabla FROM MiUsuario;
-- Deniega explícitamente (tiene mayor prioridad)
DENY SELECT ON dbo.MiTabla TO MiUsuario;
💡 Tip importante:DENY siempre tiene prioridad sobre GRANT.
Ejecutar como otro usuario (testing de seguridad)
EXECUTE AS USER = 'MiUsuario';
SELECT * FROM dbo.MiTabla;
REVERT;
🔐 Respaldos y restauracion
Identificar usuarios huérfanos
SELECT dp.type_desc, dp.sid, dp.name AS user_name
FROM sys.database_principals AS dp
LEFT JOIN sys.server_principals AS sp
ON dp.sid = sp.sid
WHERE sp.sid IS NULL
AND dp.authentication_type_desc = 'INSTANCE';
Reparar usuarios huérfanos
--Crear inicio de sesión que no existe
CREATE LOGIN <login_name>
WITH PASSWORD = '<use_a_strong_password_here>',
SID = <SID>;
--Asignar usuario huérfano a inicio de sesión existente
ALTER USER <user_name> WITH Login = <login_name>;
📊 Monitoreo y diagnóstico
Que privilegios tiene un usuario
SELECT
dp.name AS Usuario,
dp2.name AS Objeto,
perm.permission_name,
perm.state_desc
FROM sys.database_permissions perm
JOIN sys.database_principals dp
ON perm.grantee_principal_id = dp.principal_id
LEFT JOIN sys.objects dp2
ON perm.major_id = dp2.object_id
WHERE dp.name = 'TuUsuario';
A que roles pertenece un usuario
SELECT
member.name AS Usuario,
role.name AS Rol
FROM sys.database_role_members drm
JOIN sys.database_principals role
ON drm.role_principal_id = role.principal_id
JOIN sys.database_principals member
ON drm.member_principal_id = member.principal_id
WHERE member.name = 'TuUsuario';
Privilegios sobre un objeto especifico
EXECUTE AS USER = 'Usuario';
SELECT *
FROM fn_my_permissions('NombreTabla', 'OBJECT');
REVERT;
Uso de índices y tablas
SELECT
DB_NAME(database_id) AS BaseDeDatos,
OBJECT_NAME(i.object_id) AS Objeto,
last_user_seek,
last_user_scan,
last_user_lookup,
last_user_update
FROM sys.dm_db_index_usage_stats s
JOIN sys.indexes i
ON s.object_id = i.object_id AND s.index_id = i.index_id
WHERE database_id = DB_ID('TuBaseDeDatos')
ORDER BY
COALESCE(last_user_seek, last_user_scan, last_user_lookup, last_user_update) DESC;
Consultas más costosas (performance tuning)
SELECT TOP 10
qs.total_elapsed_time / qs.execution_count AS AvgElapsedTime,
qs.execution_count,
qs.total_logical_reads,
qt.text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY AvgElapsedTime DESC;
Bloqueos activos
SELECT
blocking_session_id,
session_id,
wait_type,
wait_time,
wait_resource
FROM sys.dm_exec_requests
WHERE blocking_session_id <> 0;
Sesiones activas
SELECT
session_id,
login_name,
status,
host_name,
program_name
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Actividad con Default Trace
SELECT *
FROM fn_trace_gettable(
(SELECT TOP 1 path FROM sys.traces WHERE is_default = 1),
DEFAULT
)
WHERE DatabaseName = 'TuBaseDeDatos'
ORDER BY StartTime DESC;
🧠 Buenas prácticas
Usa roles en lugar de permisos directos a usuarios
Evita usar dbo para todo, segmenta por esquemas
Aplica el principio de mínimos privilegios
Audita accesos periódicamente
Documenta cambios de seguridad
🚀 Conclusión
Estos comandos te permiten:
Administrar accesos de forma segura
Diagnosticar problemas de rendimiento
Identificar bloqueos y uso de recursos
Prepararte para escenarios reales en producción
Dominar estos scripts es clave para cualquier desarrollador backend o líder técnico que trabaje con SQL Server.
📌 Si te fue útil, considera guardar este artículo o compartirlo con tu equipo.
Firebase Cloud Messaging (FCM) de Google es un servicio que permite enviar notificaciones push a aplicaciones móviles, aplicaciones web y otros dispositivos conectados.
FCM ofrece una API HTTP que permite enviar mensajes desde servidores backend hacia dispositivos cliente de forma segura y escalable.
Las notificaciones pueden enviarse utilizando tres tipos principales de destino.
Tipos de destino de notificaciones en FCM
1️⃣ Token de dispositivo (Device Token)
Permite enviar una notificación directamente a un dispositivo específico.
Cada instalación de una aplicación genera un token único proporcionado por FCM. Este token identifica la instancia de la aplicación en ese dispositivo.
El backend puede almacenar este token para enviar notificaciones personalizadas.
2️⃣ Tema (Topic)
Los topics permiten enviar notificaciones a múltiples dispositivos usando un modelo publisher–subscriber.
Los dispositivos se suscriben a un topic y cualquier mensaje enviado a ese topic será recibido por todos los dispositivos suscritos.
Ejemplo de topics:
news promotions weather_alerts
3️⃣ Condicional
Las notificaciones condicionales permiten definir expresiones lógicas para enviar mensajes a múltiples topics.
Ejemplo:
'news' in topics && 'mexico' in topics
Esto enviará la notificación únicamente a dispositivos suscritos a ambos topics.
Autenticación con Firebase Cloud Messaging
Para enviar notificaciones usando la API HTTP v1 es necesario autenticarse usando OAuth2 mediante una cuenta de servicio de Google.
Crear la cuenta de servicio
Ir a Firebase Console
Abrir Project Settings
Seleccionar Service Accounts
Generar una nueva clave privada
Descargar el archivo:
serviceAccount.json
Este archivo contiene las credenciales necesarias para autenticarse contra la API de FCM.
Obtener un Access Token usando Google CLI
Una forma sencilla de probar las notificaciones es obtener un Access Token temporal con la CLI de Google.
En aplicaciones .NET Core / .NET 8 / .NET 9 podemos utilizar la API HTTP v1 de FCM usando las librerías de autenticación de Google.
Paquetes NuGet necesarios
--Requerido Google.Apis.Auth
--Opcionales, para un cliente de alto nivel FirebaseAdmin FirebaseAdmin.Messaging
También se puede usar directamente HttpClient, como en el siguiente ejemplo.
Ejemplo: aplicación de consola en .NET
// Program.cs (.NET 8/9)using Google.Apis.Auth.OAuth2; using System.Net.Http.Headers; using System.Net.Http.Json;// Configuración const string projectId = "TU_PROJECT_ID"; const string deviceToken = "TU_DEVICE_TOKEN"; const string topic = "news";// Obtener credenciales desde GOOGLE_APPLICATION_CREDENTIALS GoogleCredential credential = await GoogleCredential .GetApplicationDefaultAsync();credential = credential.CreateScoped( "https://www.googleapis.com/auth/cloud-platform");// Obtener access token var accessToken = await credential .UnderlyingCredential .GetAccessTokenForRequestAsync();using var http = new HttpClient();http.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", accessToken);var url = $"https://fcm.googleapis.com/v1/projects/{projectId}/messages:send";// Ejemplo 1: enviar a un device token var payloadToToken = new { message = new { token = deviceToken, notification = new { title = "Hola desde .NET", body = "Este es un mensaje de prueba vía FCM" }, data = new { accion = "abrir_detalle", id = "12345" }, android = new { priority = "HIGH" } } };// Ejemplo 2: enviar a un topic var payloadToTopic = new { message = new { topic = topic, notification = new { title = "Noticia", body = "Nueva actualización disponible" }, data = new { tipo = "update", version = "2.0" } } };// Elegir payload var body = payloadToToken;var response = await http.PostAsJsonAsync(url, body);var responseText = await response.Content.ReadAsStringAsync();Console.WriteLine($"Status: {response.StatusCode}"); Console.WriteLine(responseText);
Ejecutar la aplicación
Primero configura la variable de entorno con el archivo de credenciales.
Windows
set GOOGLE_APPLICATION_CREDENTIALS=C:\ruta\clave.json
Mi primer acercamiento al streaming de contenido multimedia comenzó con Video Station, la aplicación nativa de los NAS Synology. Aunque en su momento fue una excelente solución, con el tiempo dejó de recibir soporte, lo que me llevó a buscar alternativas. En ese proceso descubrí un ecosistema de herramientas que hoy forman parte de este pequeño compendio de aplicaciones para streaming y automatización de bibliotecas multimedia.
🔤 Bazarr: el buscador automático de subtítulos
El primer problema que quise resolver fue la búsqueda manual de subtítulos. Así fue como encontré Bazarr, una aplicación que se encarga de buscar y descargar subtítulos automáticamente para películas y series, manteniendo la colección siempre actualizada.
Bazarr fue el punto de entrada que me llevó a descubrir otras herramientas, ya que depende de ellas para funcionar correctamente.
🎬 Radarr y Sonarr: automatización total para películas y series
Radarr se encarga de buscar, descargar y organizar películas.
Sonarr hace lo mismo, pero con series de televisión.
Ambas aplicaciones funcionan de manera muy similar y se integran fácilmente con distintos clientes de descarga. En mi caso, la primera configuración la realicé utilizando redes Usenet.
🌐 Usenet: la red detrás de la automatización
Usenet es una red originalmente creada para intercambio de discusiones, pero que hoy en día también se utiliza para compartir archivos. Para conectarte y aprovechar su potencial se necesitan tres componentes básicos:
Un indexador: mantiene un registro de los archivos disponibles en la red. Existen gratuitos y de paga; yo utilicé NZBGeek.
Un proveedor de Usenet: es el servicio que te da acceso a la red. Para obtener buena velocidad de descarga conviene contratar uno de pago; en mi caso, Usenet.farm.
Un cliente de descargas: el encargado de recibir los archivos desde la red Usenet. Yo usé NZBGet, una opción ligera y eficiente.
En NZBGet configuré el proveedor de Usenet, mientras que en Radarr y Sonarr establecí la conexión tanto con el indexador como con el cliente de descargas. Una vez integrados, todo el sistema funcionaba de forma casi autónoma: buscaba, descargaba y organizaba el contenido de manera continua.
🎞️ Jellyfin: la evolución del streaming personal
Finalmente, cuando Video Station fue deprecado por Synology, opté por migrar a Jellyfin, una plataforma de código abierto que permite administrar, organizar y transmitir contenido multimedia desde cualquier dispositivo. Jellyfin se convirtió en el centro de todo mi ecosistema multimedia, reemplazando completamente a la solución original del NAS.
⚙️ Conclusión
Esta primera configuración funcionó de manera excelente. La integración entre Radarr, Sonarr, Bazarr y NZBGet permitió una automatización completa del flujo de descarga y organización de contenido, con Jellyfin como el punto final de consumo.
La única desventaja era la dependencia de servicios de pago (indexador y proveedor de Usenet), lo que me llevó a explorar alternativas basadas en torrents, de las cuales hablaré en mi siguiente publicación.
📌 En el siguiente post les platicaré sobre mi segunda configuración, esta vez utilizando torrents, y cómo logré mantener la automatización sin depender de servicios de pago.
En esta ocasión les explico cómo conectar un equipo con Linux Debian a un UPS (sistema de alimentación ininterrumpida) que está conectado a un NAS Synology, usando la herramienta NUT (Network UPS Tools).
Esto es útil para monitorear el estado de energía desde múltiples dispositivos en red y configurar apagados automáticos en caso de corte eléctrico prolongado.
🔌 Requisitos previos
NAS Synology con un UPS conectado y con la opción “Permitir que otros dispositivos de red se conecten al servidor UPS” activada.
Un equipo con Linux Debian en la misma red local.
Paquetes de NUT instalados en Debian (nut, nut-client).
🧰 Paso 1: Habilitar y configurar UPS de Red en NAS Synology
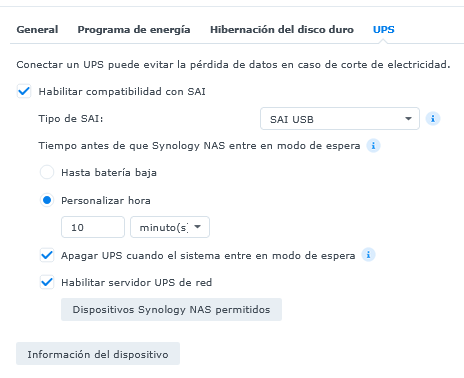
En el Panel de Control del NAS Synology, en la sección Hardware y Alimentación, en la pestaña UPS, seleccionar las opciones:
Habilitar compatibilidad con SAI
Habilitar servidor UPS de Red
Habilitar UPS NAS Synology
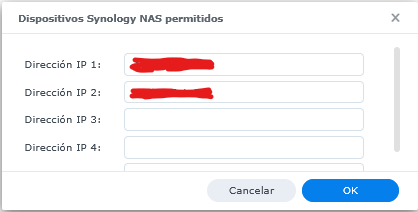
En la opción “Dispositivos Synology NAS permitidos”, agregar la ip del equipo con sistema operativo Linux
🖥️ Paso 2: Instalar NUT en Debian
Ejecuta los siguientes comandos en la consola de tu equipo Linux
sudo apt update
sudo apt install nut
⚙️ Paso 2: Configurar los archivos
Editar el archivo /etc/nut/nut.conf Agregar la siguiente linea, define que el equipo Linux Debian actuará como cliente:
MODE=netclient
Editar el archivo /etc/nut/upsmon.conf Agrega esta línea con la IP de tu NAS (y el nombre del UPS que suele ser ups):
MONITOR ups@<ip Nas Synology> 1 monuser secret slave
ups → nombre por defecto del UPS en Synology.
monuser secret → usuario/contraseña default.
slave → indica que esta máquina es un cliente del servidor UPS.
🧪 Paso 3: Verificar la conexión
Prueba si puedes obtener información del UPS desde Linux Debian:
upsc ups@<ip Nas Synology>
Deberías ver algo como:
battery.charge: 100
ups.status: OL
input.voltage: 230
...
🚀 Paso 4: Habilitar y arrancar el servicio
En el equipo linux, ejecuta los siguientes comandos de consola
Comando para ver el nombre del UPS desde el NAS (vía SSH):
upsc -l
Estado OL = On Line (todo normal).
Estado OB = On Battery (corte de energía, funcionando con batería).
Estado LB = Low Battery (batería crítica, inicia apagado).
✅ Conclusión
Con esta configuración, puedes monitorear y proteger tu equipo Linux Debian ante cortes de energía, usando el UPS conectado a tu NAS Synology como fuente central de información. Es una solución simple y robusta para entornos caseros o de oficina que mejora la seguridad de tus datos y sistemas.
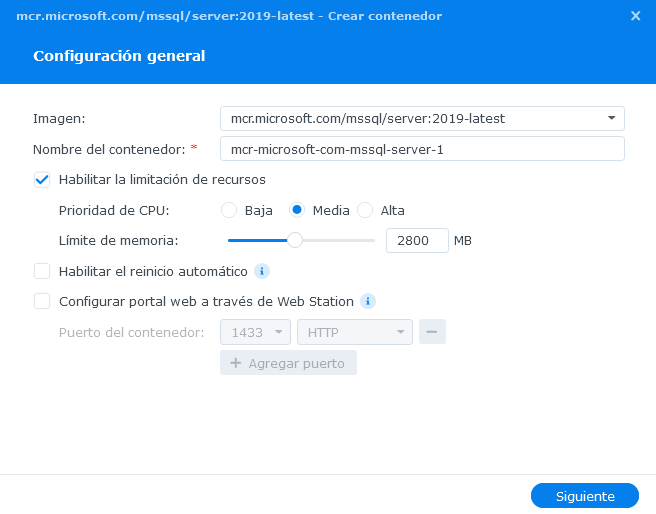
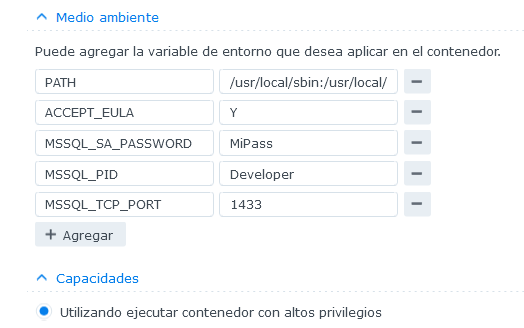
Después de varios intentos fallidos, por fin logre levantar un contenedor de SQL Server basado en Docker en mi NAS Synology.
Aquí les comento el paso a paso y los problemas que tuve al momento de levantar la instancia.
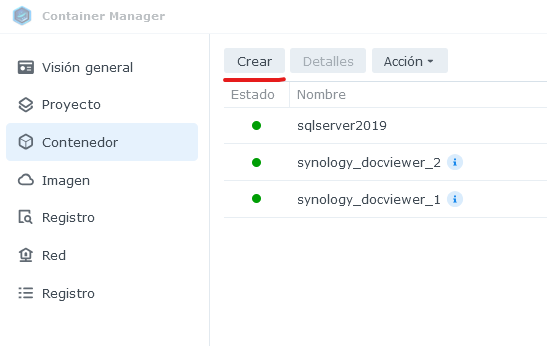
Primeramente, hay que verificar que nuestro NAS cumpla con los requerimientos mínimos, si es así, procedemos con la creación el contenedor dentro del Container Manager.
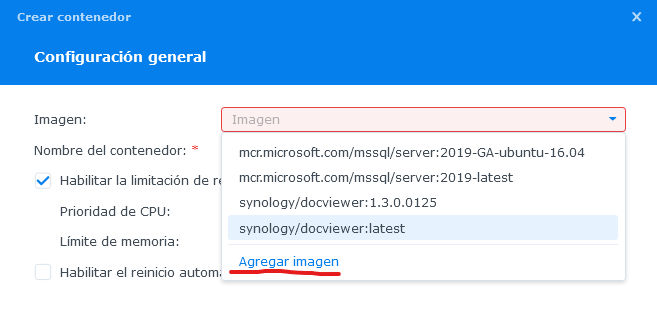
En la sección Contenedor, dar clic en el botón Crear.
En el campo Imagen, selecciona la opción Agregar Imagen.
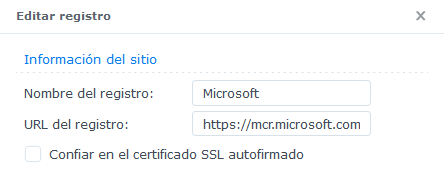
En la configuración tendrás que agregar el registro de contenedores de Microsoft https://mcr.microsoft.com
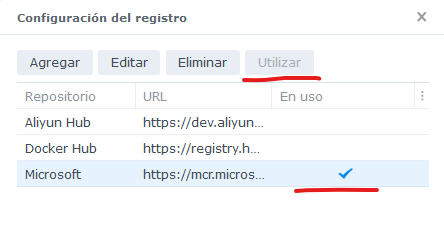
Posteriormente, seleccionarlo como el contenedor de registro a utilizar
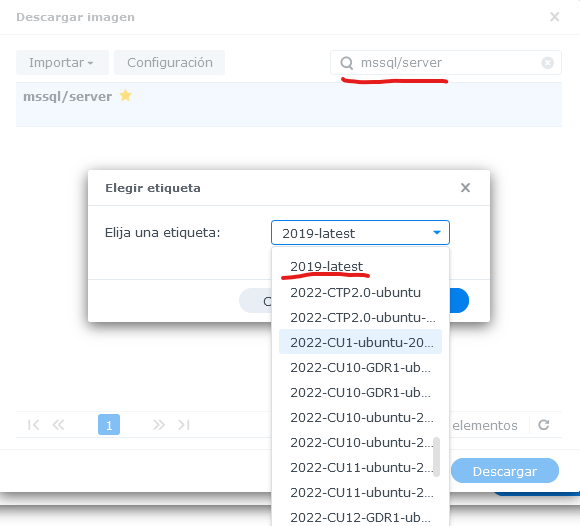
Después, buscar la imagen del contenedor de SQL Server mediante el buscador, ingresando el texto “mssql/server” en el buscador, y seleccionar la versión que se requiera.
Después, asignar un nombre y configurar los recursos a asignar a nuestro contenedor.
Para esto recomiendo utilizar prioridad de CPU media, ni alta ni baja ya que puede consumir todo nuestro CPU o puede no ser suficiente con configuración baja. Para el Limite de memoria asignar por lo menos un 30% mas de lo recomendado en los requerimientos mínimos, y muy importante, no habilitar el reinicio automático, ya que en caso de alguna falla puede entrar en un bucle de falla-reinicio infinito.
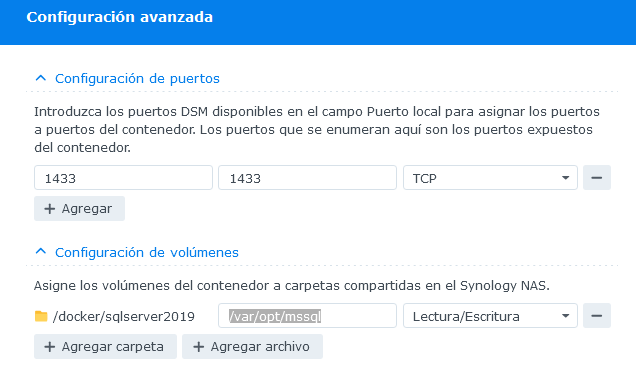
En la siguiente sección de configuración hay que asignar el puerto para nuestro contenedor, podría ser el puerto por defecto de SQL Server (1433) o algún otro.
Es importante configurar algún volumen físico de nuestro NAS a la ruta “/var/opt/mssql” del contenedor, para almacenar nuestras bases de datos fuera del contenedor y no se pierdan al apagar o reiniciar nuestro NAS.
En esta ocasión les comparto una opcion personalizada para mover o respaldar archivos en un NAS Synology mediante un script definido por el usuario, ejecutado de forma recursiva mediante el programador de tareas.
Esto puede ser util para ejecutar cualquier tipo de script, no solo para mover o respaldar archivos.
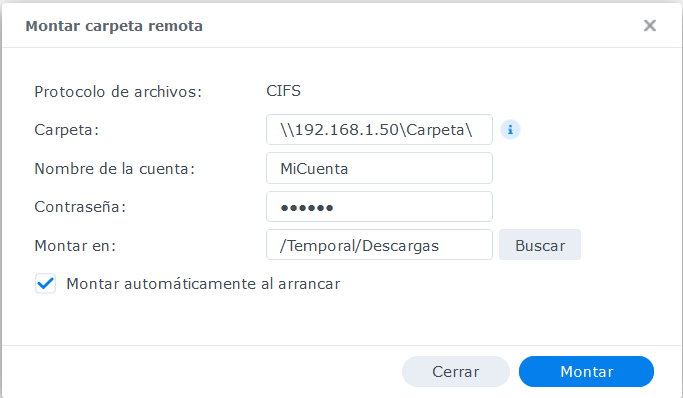
Lo primero que realice fue montar una carpeta remota, para esto abrir File Station
Ingrese al menú Herramientas / Montar carpeta remota / Carpeta compartida de CIFS e incluí las configuraciones de la carpeta remota
Posteriormente se tendría que crear el script a ejecutar y almacenarlo en algún directorio dentro del NAS
Para el script utilice comandos muy básicos de Linux, los comandos cp y rm
El script quedo de la siguiente forma:
cd /volume1/directorioorigen/
cp -uvr /volume1/directorioorigen/ /volume1/directoriodestino/
rm -rv /volume1/directorioorigen/*
El comando cp sirve para copiar archivos y el rm sirve para eliminar archivos en el sistema operativo Linux, les incluyo una descripción de las opciones que maneje:
-u
copia solo si el archivo es mas nuevo que el archivo destino o en el destino no existe
-v
–verbose explain what is being done
-r
–recursive copy directories recursively
Pienso en un futuro actualizar el script utilizando el comando rsync.
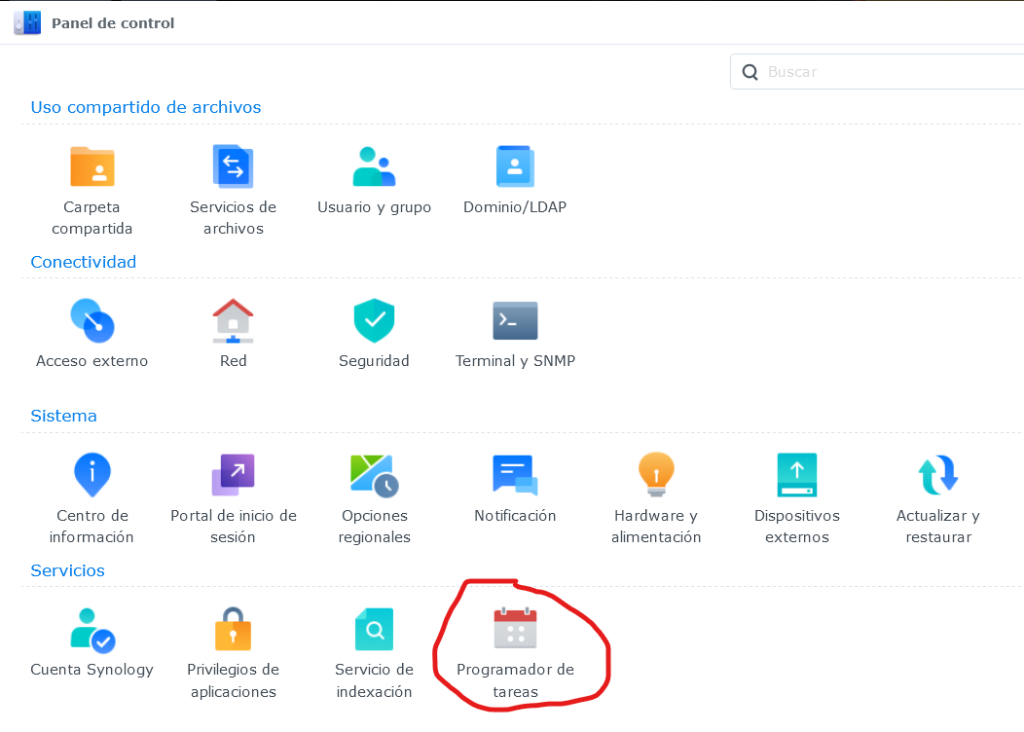
Por ultimo, para crear la tarea programada tienen que ingresar a Panel de Control / Programador de Tareas
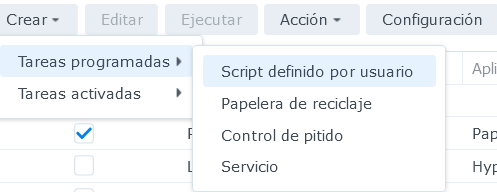
Posteriormente, al menú Crear / Tareas Programadas / Script definido por el usuario
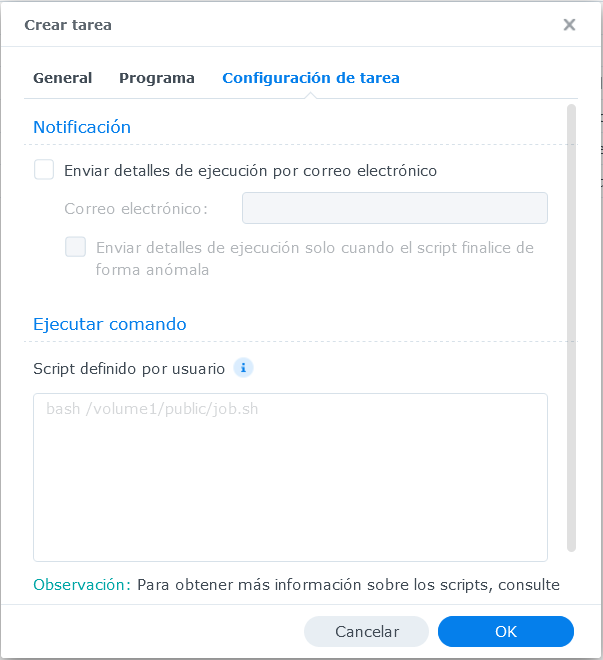
Ahí definirás el nombre de la tarea, periodicidad de ejecución y la ruta del script a ejecutar
También les recomiendo seguir las recomendaciones para guardar los resultados de la ejecución del script
Por el momento es todo, espero les sea de utilidad
En alguna ocasión, en una empresa que trabajaba, tuve problemas para acceder a las librerías de Nuget, me marcaba algunos errores de autenticación como los siguientes:
C:\Program Files\dotnet\sdk\3.1.300\NuGet.targets(128,5): error : Unable to get repository signature information for source https://api.nuget.org/v3-index/re pository-signatures/5.0.0/index.json.
C:\Users\MiUsuario\AppData\Local\Temp\fhlnaoru.gdt\restore.csproj] C:\Program Files\dotnet\sdk\3.1.300\NuGet.targets(128,5): error : Response status code does not indicate success: 407 (authenticationrequired). [C:\Users\MiUsuario\AppData\Local\Temp\fhlnaoru.gdt\restore.csproj]
En esa empresa, el navegador tenia configurado un proxy http, por lo tanto me di a la tarea de buscar como configurar dicho proxy a el componente de Nuget.
Pude identificar que el componente Nuget tiene un archivo de configuración donde se puede indicar que se conecte a internet mediante un proxy, por el momento no recuerdo cual es esa ruta, sin embargo, no creo que sea difícil ubicarla preguntando le al señor Google o a alguna IA.
Es posible configurar manualmente el proxy, editando el archivo con cualquier editor de texto, o se puede usar la consola de comandos y utilizar los siguientes comandos: nuget.exe config -set http_proxy=http://urlproxy:puerto nuget.exe config -set http_proxy.user=dominioRed\Usuario nuget.exe config -set http_proxy.password=contraseña
Posterior a esto solo es necesario cerrar y volver a abrir el Visual Studio y el componente Nuget ya tendrá acceso a los repositorios de Microsoft.